Razonamiento y pensamiento extendido
Algunos modelos pueden razonar antes de responder: resolver un problema paso a paso en lugar de contestar de una sola vez. Para la detección de PII, esa deliberación extra atrapa los casos difíciles: la fecha que solo identifica en contexto, el nombre de pila que pertenece a la persona citada en el encabezado, la institución pública que no debería ocultarse. Piixie puede activar el razonamiento, ajustar cuánto se produce y mostrártelo en directo.
Qué te aporta el razonamiento
Sección titulada «Qué te aporta el razonamiento»Un modelo que piensa primero tiende a:
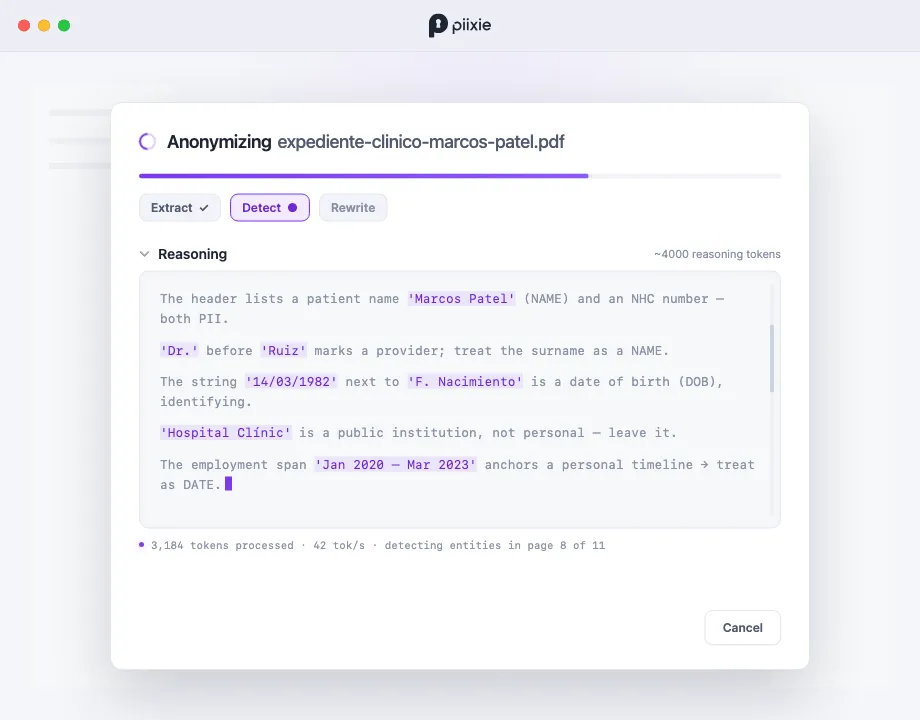
- Distinguir lo público de lo privado — dejar Hospital Clínic (una institución) mientras oculta al paciente, en lugar de ocultar de forma indiscriminada todos los nombres propios.
- Resolver referencias — reconocer que Marcos, Sr. Patel y Patel son una misma persona y tratarlos de forma coherente.
- Juzgar fechas — tratar un periodo de empleo como identificativo, pero el mes de una nota de prensa como público. (Consulta por qué LLM para la detección de PII.)
El coste es tiempo: más pensamiento implica una ejecución más lenta. Ese es el equilibrio que estás ajustando.
Niveles de esfuerzo
Sección titulada «Niveles de esfuerzo»El razonamiento se configura por modelo, como un nivel de esfuerzo:
| Nivel | Significado |
|---|---|
| Default | Usa el valor por defecto del propio modelo (los modelos locales tienden a una cantidad ligera; los remotos usan el valor por defecto del proveedor) |
| Off | Sin razonamiento — respuestas más rápidas, de una sola pasada |
| Low | Un poco de pensamiento — una pequeña mejora de calidad por un coste modesto |
| Med | Pensamiento moderado |
| High | Máximo pensamiento — mejor en documentos enrevesados, el más lento |
Como dice la pista en la aplicación: cuánto piensa el modelo antes de responder. Menos = más rápido.
Cómo configurarlo
Sección titulada «Cómo configurarlo»En Settings → Models, cada modelo tiene un control de Reasoning:
- Override reasoning para elegir un nivel para ese modelo.
- Reset to default para devolverle la decisión al modelo.
La elección se recuerda por modelo, así que tu modelo rápido del día a día puede quedarse en Low mientras un modelo remoto de frontera que reservas para documentos difíciles se queda en High.
Qué modelos lo admiten
Sección titulada «Qué modelos lo admiten»- Modelos Gemma locales — el razonamiento se admite a través de llama.cpp; Piixie pasa un presupuesto de pensamiento dimensionado según el nivel de esfuerzo.
- Anthropic — usa el pensamiento extendido de la Messages API, con un presupuesto de tokens escalado según el nivel.
- Compatible con OpenAI — usa el ajuste de reasoning-effort del proveedor.
Para los endpoints remotos, si un modelo admite razonamiento se detecta automáticamente cuando Piixie obtiene la lista de modelos, y se muestra como una capacidad de Reasoning que puedes activar para forzarla si la detección es incorrecta.
Verlo en acción
Sección titulada «Verlo en acción»Cuando el razonamiento está activo, el diálogo de procesamiento muestra una sección de Reasoning. El pensamiento del modelo fluye a medida que trabaja: lo verás sopesar cada entidad (“‘Hospital Clínic’ es una institución pública, no personal — déjala”) antes de decidirse. Un pequeño contador de tokens muestra aproximadamente cuánto pensamiento ha hecho.
Esto no es solo decorativo: ver el razonamiento da confianza en el resultado, y cuando el modelo se equivoca en algo, el pensamiento a menudo te dice por qué, útil cuando vas a editar el resultado o a ajustar un prompt de perfil.
Cuándo subirlo
Sección titulada «Cuándo subirlo»- Subir (Med/High): documentos densos y ambiguos —historiales médicos, contratos, cualquier cosa donde el contexto decide qué es PII.
- Bajar (Low/Off): documentos sencillos y de alto volumen donde importa la velocidad y la PII es evidente.